CLIP 系列
介绍
CLIP (Contrastive Language-Image Pre-Training) 是 OpenAI 在 2O21 年发布的一个预训练模型,用于匹配图像和文本。它是多模态研究领域的经典之作。
论文: Learning Transferable Visual Models From Natural Language Supervision
模型结构
CLIP模型包含两个主要部分:
- Text Encoder:用于对文本进行编码,生成文本的 Embedding。采用经典的 Text Transformer 模型。
- Image Encoder:用于对图片进行编码,生成图片的 Embedding。作者还尝试了 ResNet、EfficientNet、Transformer、最大用了ViT。 这两个 Encoder 生成的 Embedding 都是固定长度的单一向量。
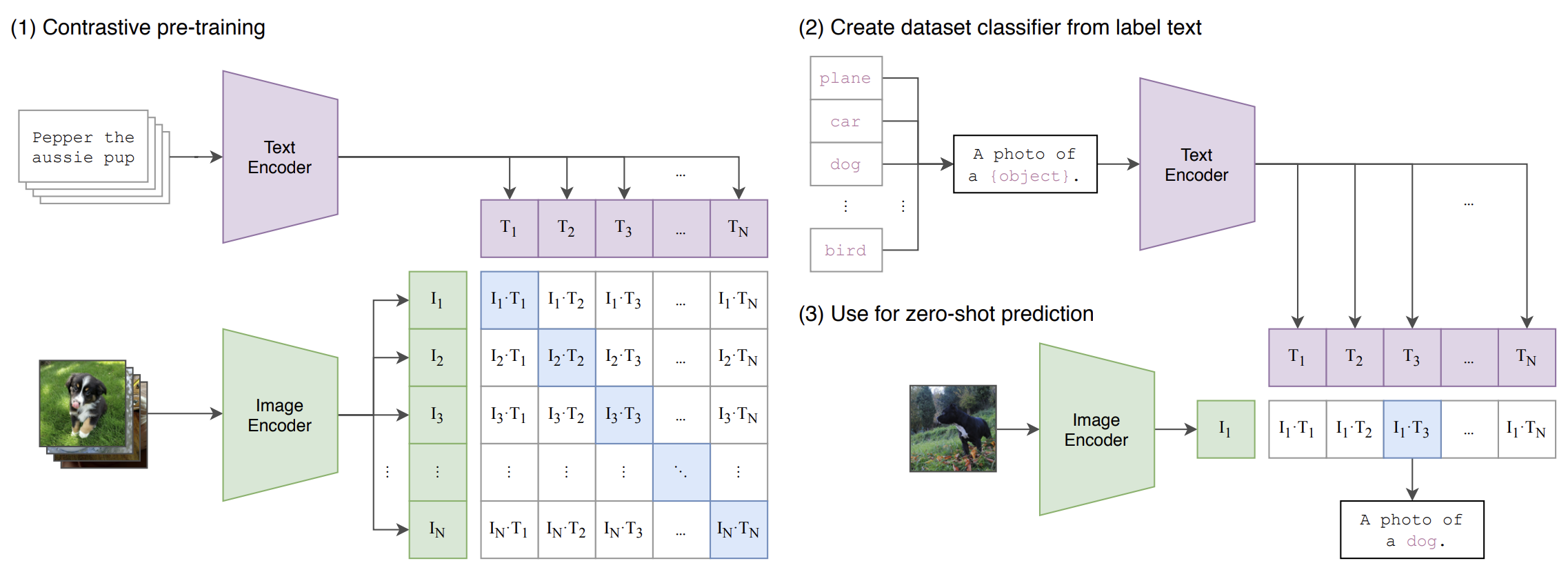
训练原理
CLIP 的训练过程基于对比学习,具体步骤如下:
- 数据格式:假设一个批次中有 64个文本图像对,每个对包含一个文本和一个图像。
- 编码:通过 Text Encoder 和 Image Encoder 分别生成文本和图像的 Embedding,得到 :
- :
- :
- 正负样本:
- 对于每个文本,其他 63 个图像是负样本。
- 对于每个图像,其他 63 个文本是负样本。
- 相似度计算:使用 visual_embedding 和 text_embedding 进行叉乘,得到一个 的矩阵。矩阵对角线上的值是成对特征的内积,表示正样本的相似度。
- 损失计算:对于每一行(即每个图像与所有文本的相似度),将正样本的标签设置为1,使用交叉熵损失函数进行训练,目标是使正样本的内积尽可能大。
CLIP 系列
https://guokent.github.io/papernotes/clip/